Method
Published Papers

Extraction of content

|
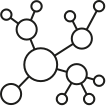
Document space: Each document is placed in a multi-dimensional space according to the distribution of words within it. Each document has a unique signature, according to the frequency of every word appearing in it. |
 Algorithmic representations of the document space.
Algorithmic representations of the document space.
1. Creation of document topics:
Based on patterns of word distributions in documents, words can be grouped into clusters of similar meaning, resulting into coherent topics such as “chemistry” or “shamanism”. Each document can then be allocated to one or more topics according to its contents.
2. The role of words within document and author topics.
Every topic is represented by the most important words characterizing it. Given that a word can influence multiple topics, we can either explore topics by words, or explore words by their role within topics.
In this project, we have divided the words space into 10 and 20 topics, creating 2 topic models.
Development Roadmap
1. Creation of author topics.
Authors allocation into topics by grouping their publications according to word clusters. As a result, authors will be distinguished and grouped according to the variety of contributions they have authored.
The aim is to create a map of authors showing their respective inclinations.
2. Locations and time.
Using geographical location and date as filters on the above mapping, we could visualize historical aspects of the scientific literature.
For example, how topic interests evolved through time, at what pace the literature has grown, who are the recurring authors, what are the countries which produced most contributions about Ayahuasca, etc.
Playing with time and space cursors can lead to many new global insights about the evolution of the scientific literature.